清华大学等单位研究者联合发布“面向中文长文本理解和生成的新基准和新模型”
近日,清华大学交互式人工智能课题组联合华为、网易的研究者联合发布了LOT---面向中文长文本理解和生成的新基准和新模型。众所周知,标准的多任务benchmark对于发展可泛化的预训练模型非常重要,现有的NLP benchmark (如GLUE、GLGE等) 大多仅仅关注理解或者生成短文本。相对来说,建模长文本相比于短文本要求许多独特的能力,比如建模长程的常识和篇章关系、生成的连贯性和可控性等。缺少标准化的benchmark使得评估和比较不同模型的这些能力非常困难,尤其是中文预训练模型。因此,研究者提出了LOT:一个评价中文本理解和生成能力的benchmark。LOT包括2个理解任务和2个生成任务。基于从网络上爬取的人类撰写的中文故事,研究者为这些任务构建了新的数据集。
此外,研究者提供了一个新的中文长文本预训练模型LongLM,来促进提高中文长文本建模能力。LongLM基于Encoder-Decoder架构,并在120G小说语料上进行预训练。LongLM有3个不同参数规模的版本,分别是small(6千万参数)、base(2亿参数)、large(10亿参数)。在LOT上的评估结果表明,LongLM比相似规模的预训练模型有更好的长文本建模能力。在本文中,研究者也将在高中作文写作和知乎问答两个场景下对LongLM的生成效果进行案例分析。

开放端长文本生成 (Open-Ended Long Text Generation) 是自然语言生成 (NLG) 中非常重要但极具挑战性的任务。所谓“开放端”是指输入中仅仅包含生成目标输出所需的少量信息,如故事生成、作文生成等任务。相对地,机器翻译、文本摘要这类生成任务则属于非开放端生成。开放端长文本生成的研究具有重要意义,首先,探索文字内容创作的内在机理能够助力实现掌握语言智能的类人AI;其次,开放端长文本生成在娱乐、教育、人机交流等方面也有重要的应用价值。
尽管开放端长文本生成具有重要的研究价值,但目前学术界却面临着缺乏高质量数据的难题。下表展示了部分常用的长文本数据集。

表1: 主流的长文本数据集
一方面,上述数据集都是英文数据,在中文领域暂无高质量的长文本数据集、及标准的长文本理解和生成任务,这极大的限制了中文长文本模型的发展;另一方面,这些英文数据要么人工痕迹过重、偏离真实场景 (如ROCStories);要么文本过长 (大于500词,如WikiText等),语言现象极其丰富,远远超过当前机器学习模型的发展水平,因此它们常用于计算语言模型的Perplexity,但难以为改进语言模型真正提供指导。
为了解决数据匮乏的问题,研究者提出了LOT,一个新的评价中文长文本理解和生成能力的benchmark (Chinese LOng Text Understanding and Generation)。与GLUE、GLGE这类以任务为中心构建的benchmark不同,它们最初的设计目标是覆盖尽可能多的任务形式,LOT以能力评价为中心,研究者用两个理解任务和两个生成任务分别来评价不同的长文本建模能力,因此LOT能够为发展长文本模型提供更细粒度的指导和更全面的评价。下表展示了LOT中四个任务的概览。

表2: LOT任务概览
基于从网络上爬取的中文故事(如童话、寓言、短篇小说等),通过自动标注和人工标注为这些任务构造了新的高质量数据集,每个样例均要求理解或者生成100-300字(5-10句话)的长文本。这些数据集的统计量如下表所示。

表3: LOT数据集统计量,每个单元格的三个数字分别表示训练集、验证集和测试集
研究者通过人工标注来构建该任务的训练集、验证集和测试集。给定一个故事样例,要求标注者选择一个可以基于常识和上下文推理出的句子,作为正确候选,然后将其重写为一个违背常识的句子,作为错误候选。常识定义为“角色的反应和意图、或者客观事物的属性”。下表展示了几个测试样例。

表4: 故事情节完形填空示例
因为文本中的句子不一定只有一个合理的位置,所以研究者通过随机删除一句话来自动标注构建该任务的训练集,并通过人工筛选只有一个合理位置的句子来构建验证集和测试集。注意源文本不一定是完整的故事。该任务主要考查模型对句间关系的理解能力,如时序、因果等关系。下表展示了几个测试样例。
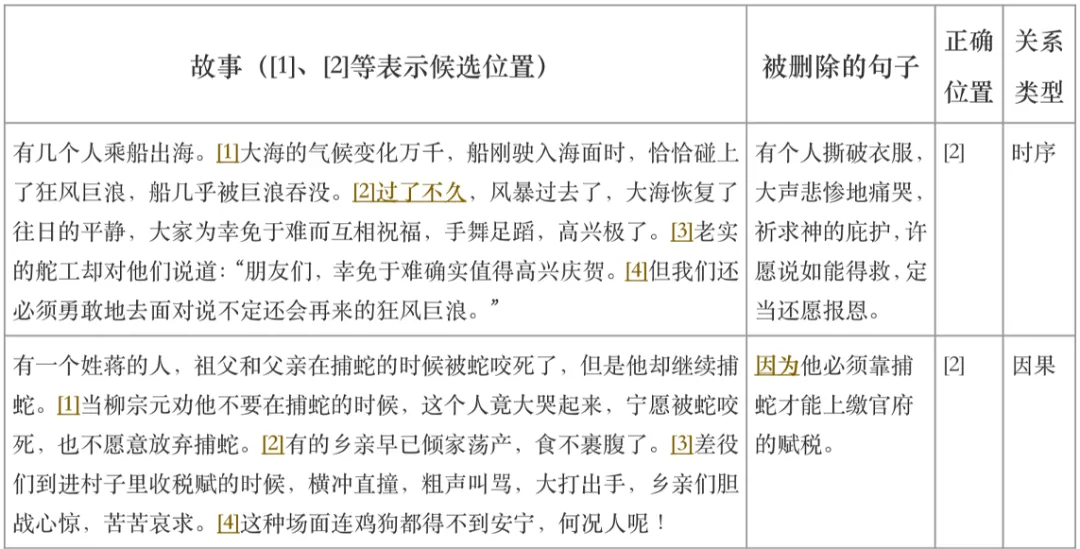
表5: 句子位置预测示例
通过自动标注来构建该任务的训练集,即从故事中随机删除一句话作为目标输出,把剩下的上下文作为输入。但是因为故事中的句子并非都能够通过常识和上下文推理得到,所以研究者从故事情节完形填空的数据集中采样了一部分数据作为该任务的验证集和测试集,在这些数据中标注者已经标注出了符合条件的句子。把正确候选当做待生成的句子,把故事上下文作为输入。
通过自动标注来构建该任务的训练集、验证集和测试集,即从故事中抽取部分短语打乱顺序后作为输入,把整个故事当作目标输出。
LongLM基于Encoder-Decoder架构,词表大小为32,000,Encoder和Decoder的最大长度均设为512。LongLM有三个不同参数规模的版本,不同规模的模型对应的参数设置如下表所示:

表6: LongLM参数设置
研究者收集了120G小说语料作为LongLM的预训练数据,这些数据覆盖了多样的话题,如言情、军事、历史等。因为一篇小说的长度远超过LongLM输入输出的最大长度,所以研究者把这些小说数据切割成不同的部分来预训练。
LongLM包含两种预训练任务,包括文本填空任务和条件续写任务。对于文本填空任务,研究者从文本中随机扔掉一些span,这些span的长度服从lambda=3的泊松分布,并且这些span的总词数约占文本总词数的15%,模型的目标是依次预测这些span的内容。对于条件续写任务,模型的目标是为给定故事的上文续写下文。两个预训练任务的示意图如下所示:

图1: LongLM预训练任务的输入输出形式示意图,
预训练的batch size为1000,学习率为1e-4,训练步数为2.5M步,并使用DeepSpeed框架进行加速。
从训练数据中随机划分出了1000个样本(未经过训练)作为测试集,用于测试不同版本的模型在两个预训练任务上的表现。评价结果如下所示:

表7: 不同参数规模的模型在两个预训练任务上的表现
不同模型在两个理解任务上的表现如下表所示:

表8: 不同模型在理解任务上的accuracy,#P表示模型参数,ClozeT表示故事情节完形填空任务,SenPos表示句子位置预测任务
不同模型在两个生成任务上的表现如下表所示:
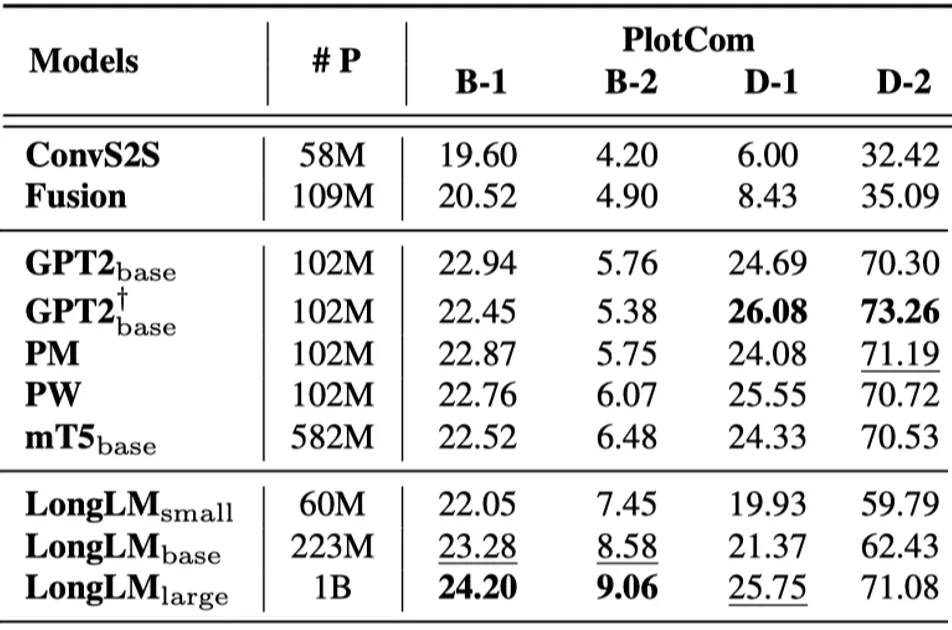
(a) 故事情节补全任务
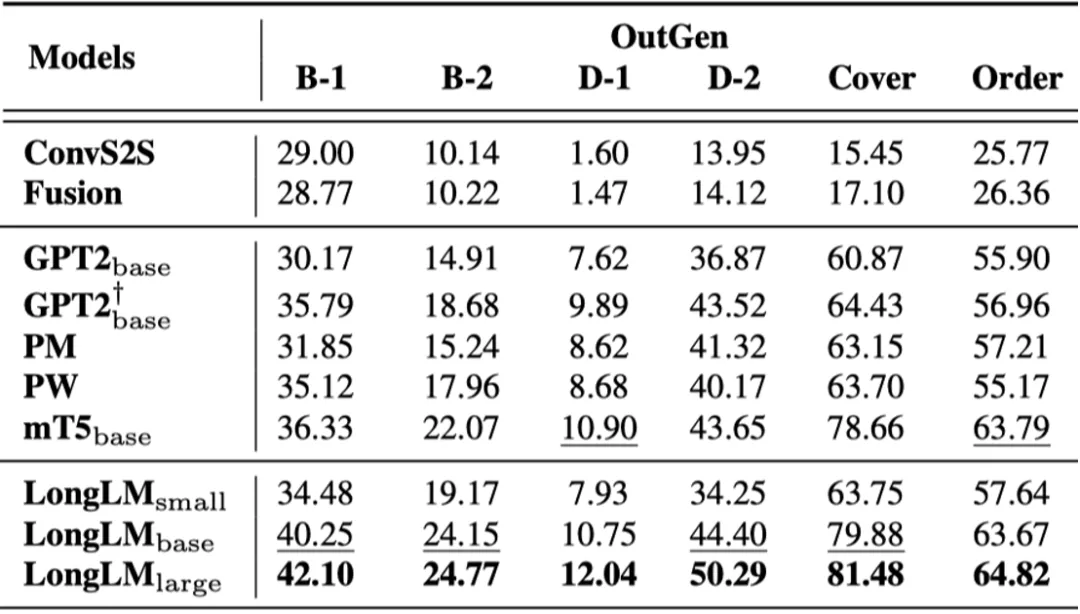
(b) 基于大纲的条件生成任务
表9: 不同模型在生成任务上的accuracy,#P表示模型参数,PlotCom表示故事情节补全任务,OutGen表示基于大纲的条件生成任务,B表示BLEU,D表示Distinct,Coverage和Order分别用于测试对输入大纲的覆盖度和顺序恢复程度
分析:
(1) LongLM-large显著好于所有基线模型;
(2) LongLM-base好于mT5,LongLM-small好于GPT2,并且参数量少一半;
(3) 现有的模型仍然难以捕捉常识和篇章关系,以及生成连贯、多样、逻辑合理的文本。
研究者用LongLM-large在4000篇高中作文上进行了微调,输入为作文的标题和第一段,输出为剩余的作文内容。下面我们看2篇LongLM的“创作”样例:
(一)可为与有为
中国共产党走过百年历程。在党团结带领人民进行的伟大斗争中孕育的革命文化和社会主义先进文化,已经深深融入我们的血脉和灵魂。我们心中有阳光,我们脚下有力量。我们的未来将融汇于中华民族伟大复兴的新征程,我们处在一个大有可为的时代。(模型输入)
在中华民族的历史长河中,有多少英雄豪杰在伟大的斗争中成长,又有多少可为之士在艰苦的奋斗中不懈地奋斗,在艰难的抉择中不屈不挠地拼搏,在无数的艰难险阻中不渝地奋进,在辉煌的胜利中不息地努力,在苦难的考验中不离不弃。 当太阳从东边升起来的时候,从西边的山头落下来的时候,又是多少可歌可泣的英雄壮举在历史的画卷上绽放!
可为与有为是相互依存的,在人生的征途上,当我们遇到挫折时,不要退缩,勇敢地伸出援助之手;当我们在困难时,要坚强地挺起胸膛,昂起头颅;当困难来临时,不要灰心丧气,勇敢地面对,昂首挺胸地走过;当挫折来临,不要心灰意冷,冷眼旁观,漠不关心,微笑着面对。
可为和有为是相辅相成的,相互促进发展的。当新中国成立之时,中国人民团结起来,团结抵抗外来侵略。经过千百年的艰苦奋斗。终于在新中国建立之初,创造了一个又一个的奇迹。中国人民从一个贫穷落后的小国,发展到今天的世界第二大经济体。在这期间,中国发生了多少大大小小的变革,经历了多少风雨。在这些变革中,我们看到了中国人民的可贵,看到了人民的伟大。在这一刻,我们心中充满了自豪,充满了骄傲。
我相信,当今世界,会有更多的可为者。当今社会,科技发达,科技飞速发展,人民生活安居乐业,我们的社会也正发生着翻天覆地的变化,我们不再是那个任人揉捏的小鸡,而是一个真正的强者。我们心中的可为,就是我们手中的这股力量,我们要将它发挥得淋漓尽致,使它成为我们的脊梁,使我们的祖国更加富强。
点评:该题目是2021年全国甲卷高考作文题。LongLM的创作还算通顺连贯,但仍然会出现“重复”的低级错误(红色斜体标出)。此外,LongLM很善于用排比句增强气(第二段、第三段紫色下划线标出),并且记住了一些客观事实(如中国是第二大经济体),最后一段甚至能够呼吁呐喊我们应该贡献自己的一份力量,令人振奋不已。但是通篇来看,LongLM似乎没有理解“可为”与“有为”的内涵,使得整篇文章内容空洞,第三段谈到“挫折”也有跑题之嫌。
(二)信念是人生的太阳
盘古开天地,人类一路从洪荒走来,经过岁月风霜雨露班的吹打,经过时空如火般的锻造,人类终于度过茹毛饮血的疯狂时代,逐渐的抛弃愚昧,拾起文明。而信念就如一刻永远璀璨的明星,指引人类前进的道路。(模型输入)
信念是走向成功的第一步,是走向辉煌的第一步。古人云:“天将降大任于斯人也,必先苦其心志,劳其筋骨,饿其体肤,空乏其身,行拂乱其所为,所以动心忍性,曾益其所不能。”的确,对于一个人来说,信念就是生命中的一盏明灯,照亮我们前进的路;而对于一个民族来说,一个民族只有一个信念,那就是战胜一切艰难险阻,奋发图强,才能取得人生的辉煌。
“人生自古谁无死,留取丹心照汗青。”是的,只有战胜了一切,才能获得胜利,才能到达理想的彼岸,才能实现自己的理想,实现自己的人生价值。所以,在人生的旅途中,我们要坚守自己的信念, 坚持不懈,不懈不懈地走下去,才能战胜一切困难,走向成功的彼岸。
古往今来,多少英雄豪杰,在他们的身上体现了无与伦比的人格魅力,让无数人为之倾倒,为之自豪。正是因为他们的人格的强劲和坚强,才有了“史家之绝唱,无韵之离骚”的千古绝唱。在他们的身上,体现的不仅仅是人格的魅力,更是信念的魅力。信念是生命中不可缺少的一滴水,是人生中永恒的闪光点,是人类前进的动力,是永不泯灭的源泉。
一个人的一生,无论是成功还是失败,都离不开信念的支撑。一个人要想成功,就必须要有信念,要有勇气,要敢于直面困难,勇往直前,不畏艰险,敢于拼搏。正是有了这股勇气和这股信念,才会有“史铁生”这般不屈不挠的精神,才能说出“人固有一死,或重于泰山,或轻于鸿毛”的豪言壮语。正是这股不屈的信念,才能让我们在人生的道路上,一路高歌,一路走好,才能走好人生的每一步。
当今社会,人们对于信念的追求是越来越高,对未来的憧憬也越来越坚定。于是,在许多人的推动下,一个个有志青年走出了黑暗的泥潭,走向了光明的大道。在他们身上体现的,不仅是对前途的追求,更是对成功信念的坚定信念。正是这种坚定的信念,支撑着他们一步步走向成功,一步步走进成功之门。
让我们勇敢地面对困难,勇敢地去拼搏吧!让我们像海伦凯勒和贝多芬那样,坚强地走过人生的每一步,为了自己的理想,去奋斗吧!
点评:相比于“可为与有为”,“信念”对于机器来说就更容易理解了。LongLM能联想到许多相关的人物,如文天祥、司马迁、史铁生、海伦凯勒等(紫色下划线标出),但是在利用这些人物表述论点时,LongLM只能做到空喊口号,缺乏论证过程,逻辑性有所欠缺。此外,整篇文章的结构也比较松散,也会出现“重复”、“搭配不当”等错误(红色斜体标出)。
可以看出,LongLM能生成比较通顺连贯的作文,但仍然难以理解复杂的概念(“可为”、“有为”)、常识和逻辑推理能力较弱(如通过论据论证论点),这些方向将是以后集中精力攻克的难题。
研究者用LongLM-large在200万个知乎问答对上进行了微调,输入为一个以问号结尾的问题,输出为相应的回答。下面我们看2个LongLM“创作”的答案(下文的回答均未在训练数据中出现过):
LongLM:人最好的生活状态是什么样子的?我不知道,我只知道我现在过的很好,每天都开开心心的,不开心的时候想吃什么就吃什么,想去哪就去哪,想做什么就去做什么,不用顾虑别人的眼光,也不用担心别人的目光,不用担心别人对自己的看法,不用害怕别人对自己的评价,不用因为别人的评价而难过伤心,我觉得我很幸福。
LongLM:谢邀。如果你很善良,那么你可以接受无理的批评,但如果你接受不了,那你还是善良吗?如果你不接受批评,你还能接受什么呢?你能接受的是无理批评,而不是你自己。我觉得你可以和你身边的人沟通一下,看看他们有没有和你一样的想法。如果没有,那就当我没说。如果他们觉得你是个善良的人,那么我觉得他们应该尊重你的选择。
点评:在第1个开放式的不涉及领域知识的问答中,LongLM的回答表现出了一定的合理性。但对于需要逻辑推理的问题(如问题2),LongLM的回答则较为混乱,这个结论和在作文生成任务中的观察是一致的。因此,提高预训练模型的推理能力将是未来研究的重要课题。
在本文中,研究者为中文长文本理解和生成提供了一个新的多任务benchmark——LOT,它包括2个理解任务和2个生成任务,全面地考查了长程的常识推理能力、可控生成能力、建模句间关系和篇章结构的能力。研究者为4个任务提供了标准的数据集。此外,研究者开源了一个新的中文长文本预训练模型LongLM,在LOT上的实验表明LongLM的长文本建模能力显著优于相似规模的预训练模型。研究者也在高中作文生成、知乎问答两个下游任务上对LongLM做了案例分析,表明提高长文本预训练模型的推理能力、规划能力、常识知识仍是未来研究的重要问题。
作者免责声明:本项目所提供的数据集和预训练模型仅限科研用途。LOT数据集中的语料收集自不同的来源,虽然作者设计了一套严格的数据清洗流程,但是并不保证所有不当内容均已被过滤。该数据中所包含的所有内容和意见与本项目作者无关。 本项目所提供的模型和代码仅为完整长文本生成系统的一个组成部分,所提供的解码脚本仅限科研用途,使用本项目中的模型和脚本所生成的一切文本内容与本项目作者无关。
LOT benchmark论文初稿:https://arxiv.org/abs/2108.12960
LOT benchmark 代码&数据:https://github.com/thu-coai/LOT-Benchmark
开放端文本生成论文列表:https://github.com/thu-coai/PaperForONLG
清华大学CoAI小组主页:http://coai.cs.tsinghua.edu.cn/
撰稿:关健
致谢:刘子奇 冯卓尔 陈雅玫
编辑:李丕绩